Контрольная работа
по курсу «Экспериментальная психология и
системный анализ данных»
на тему «Анализ данных»
Выполнила студентка 2 курса 7 группы
Заочного отделения
Кемза Екатерина Владимировна
Преподаватель Иванов С.А.
Гродно 2014
Задание 1. Выявить различия в уровне исследуемого признака в независимых группах 1 и 2 (а принять равным 0,05).
|
1 |
136 |
134 |
134 |
127 |
119 |
124 |
127 |
123 |
123 |
|
2 |
132 |
135 |
141 |
136 |
132 |
129 |
127 |
132 |
124 |
Решение.
Сформулируем гипотезы:
Но: Уровень признака в группе 1 не ниже уровня признака в группе 2
Hi: Уровень признака в группе 1 ниже уровня признака в группе 2
Воспользуемся U-критерием Манна-Уитни
Проранжируем выборки
|
Значение признака |
Принадлежность к группе |
Rl |
R2 |
|
119 |
1 |
1 |
|
|
123 |
1 |
2,5 |
|
|
123 |
1 |
2,5 |
|
|
124 |
1 |
4,5 |
|
|
124 |
2 |
4,5 |
|
|
127 |
1 |
7 |
|
|
127 |
1 |
7 |
|
|
127 |
2 |
7 |
|
|
129 |
2 |
9 |
|
|
132 |
2 |
11 |
|
|
132 |
2 |
11 |
|
|
132 |
2 |
11 |
|
|
134 |
1 |
13,5 |
|
|
134 |
1 |
13,5 |
|
|
135 |
2 |
15 |
|
|
136 |
1 |
16,5 |
|
|
136 |
2 |
16,5 |
|
|
141 |
2 |
18 |
|
|
Сумма |
68 |
103 |
|
Общая сумма рангов
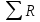 1+
1+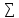 R2 = 68 +103 = 171
R2 = 68 +103 = 171
Рассчитанная сумма
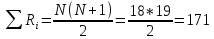
Равенство реальной и расчетной
сумм соблюдены.
Определим эмпирическую величину u:
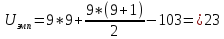
Определим критическое значение u по таблице критических значений U-критерия Манна-Уитни при а=0,05:
Uкр; 0,05 = 27
Так как Uкр; 0,05> Uэмn, то гипотезу Но
отвергаем: Уровень признака в группе 1 отличается от уровня признака в группе 2.
Задание 2. Оценить силу связи между признаками 1 и 2 (а принять равным 0,05).
|
1 |
-11 |
-12 |
-12 |
16 |
11 |
12 |
12 |
13 |
13 |
13 |
|
2 |
2,8 |
2,3 |
2,8 |
3,6 |
4 |
4,7 |
4,7 |
4,7 |
5 |
5 |
Решение.
Сформулируем гипотезы:
Но: Корреляция между признаками 1 и 2 не отличается от нуля
Н1: Корреляция между признаками 1 и 2 статистически значимо отличается
от нуля
Проранжируем оба показателя. Произведем все вычисления в таблице:
|
№ п/п |
Признак 1 |
Признак 2 |
d (ранг 1-ранг 2) |
d2 |
||||
|
|
Значение |
Ранг |
Значение |
Ранг |
|
|
||
|
1 |
-11 |
1 |
2,8 |
2,5 |
-1,5 |
2,25 |
||
|
2 |
-12 |
2,5 |
2,3 |
1 |
1,5 |
2,25 |
||
|
3 |
-12 |
2,5 |
2,8 |
2,5 |
0 |
0 |
||
|
4 |
16 |
10 |
3,6 |
4 |
6 |
36 |
||
|
5 |
11 |
4 |
4 |
5 |
-1 |
1 |
||
|
6 |
12 |
5,5 |
4,7 |
7 |
-1,5 |
2,25 |
||
|
7 |
12 |
5,5 |
4,7 |
7 |
-1,5 |
2,25 |
||
|
8 |
13 |
8 |
4,7 |
7 |
1 |
1 |
||
|
9 |
13 |
8 |
5 |
9,5 |
-1,5 |
2,25 |
||
|
10 |
13 |
8 |
5 |
9,5 |
-1,5 |
2,25 |
||
|
Суммы |
55 |
55 |
51,5 |
|||||
Коэффициент ранговой корреляции Спирмена подсчитывается по формуле:
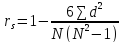 , где d — разность между рангами по двум переменным для
, где d — разность между рангами по двум переменным для
каждого испытуемого; N — количество ранжируемых значений. Рассчитаем эмпирическое значение 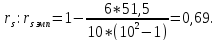
Полученное эмпирическое значение rs эмп близко к 1.
Определим критическое значение rs при N=10 и а=0,05 по таблице критических значений выборочного коэффициента корреляции рангов:
rs кр = 0,64.
Так как rsэмп >rsкр, то Н0 отвергаем. Значит, корреляция между признаками 1 и
2 статистически значимо отличается от нуля, т.е. между признаками 1 и 2 существует связь. Т.к. rsэмп = 0,69, то можно говорить о достаточно тесной
связи между признаками 1 и 2.
Задание 3. Оценить достоверность сдвига в значениях исследуемого признака в зависимых группах 1 и 2 (а принять равным 0,05)
|
1 |
-11 |
-12 |
-12 |
16 |
11 |
12 |
12 |
13 |
13 |
13 |
|
2 |
2,8 |
2,3 |
2,8 |
3,6 |
4 |
4,7 |
4,7 |
4,7 |
5 |
5 |
Решение.
Сформулируем гипотезы:
Н0: Интенсивность положительных сдвигов не превосходит интенсивности отрицательных сдвигов
Н1: Интенсивность положительных сдвигов превосходит интенсивности отрицательных сдвигов
Воспользуемся Т-критерием Вилкоксона
|
Значение признака 1 группы |
Значение признака 2 группы |
Разность 1 — 2 |
Абсолютное значение разности |
Ранговый номер разности |
|
-11 |
2,8 |
-13,8 |
13,8 |
8 |
|
-12 |
2,3 |
-14,3 |
14,3 |
9 |
|
-12 |
2,8 |
-14,8 |
14,8 |
10 |
|
16 |
3,6 |
12,4 |
12,4 |
7 |
|
11 |
4 |
7 |
7 |
1 |
|
12 |
4,7 |
7,3 |
7,3 |
2,5 |
|
12 |
4,7 |
7,3 |
7,3 |
2,5 |
|
13 |
4,7 |
8,3 |
8,3 |
4 |
|
13 |
5 |
8 |
8 |
5,5 |
|
13 |
5 |
8 |
8 |
5,5 |
|
55 |
Сумма рангов равна 55, что соответствует расчетной
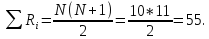
Теперь отметим те сдвиги, которые являются отрицательными.
Сумма рангов этих сдвигов и составляет эмпирическое значение критерия Т:
T эмп = 27.
По таблице критических значений Т-критерия Вилкоксона определяем критическое значение Т для N=10 и а=0,05 : Ткр(0,05) = 10.
Так как Тэмп > Ткр(0,05), то H0 принимаем. Интенсивность положительных сдвигов не превосходит интенсивности отрицательных сдвигов.
Задание 4. Выявить влияние фактора на результаты исследования.
Три группы баскетболистов занимались на базе одной ДЮСШ по разным программам специальной подготовки. Эффективность программы оценивалась по уровню общефизической подготовки. Одним из упражнений был бег на 100м. В каждой группе было по 10 человек. Оценить влияние программ на полученные результаты.
|
1-й вид подготовки |
11,6 |
12,3 |
11,8 |
12,1 |
12,8 |
13,2 |
13,8 |
12,0 |
12,6 |
13,0 |
|
2-й вид подготовки |
11,3 |
12,8 |
12,2 |
11,7 |
12,4 |
13,3 |
11,4 |
12,0 |
11,8 |
12,5 |
|
3-й вид подготовки |
11,4 |
11,9 |
11,5 |
12,6 |
12,7 |
12,6 |
11,8 |
12,0 |
12,6 |
13,5 |
Решение.
Составим таблицу:
|
|
1-й вид подготовки |
2-й вид подготовки |
3-й вид подготовки |
|
12,6 |
11,3 |
12,4 |
|
|
12,3 |
12,8 |
11,9 |
|
|
11,8 |
12,2 |
11,5 |
|
|
12,1 |
11,7 |
12,6 |
|
|
12,8 |
12,4 |
12,7 |
|
|
13,2 |
13,3 |
12,6 |
|
|
13,8 |
11,4 |
11,8 |
|
|
12 |
12 |
12 |
|
|
12,6 |
11,8 |
12,6 |
|
|
13 |
12,5 |
13,5 |
|
|
Итого: |
126,2 |
121,4 |
123,6 |
Для проведения дисперсионного анализа воспользуемся следующим:
1. Рассчитаем Q1 – сумма квадратов всех наблюдений
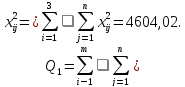
2. Рассчитаем Q2 – сумма квадратов итогов по столбцам, деленное на число наблюдений в столбце:
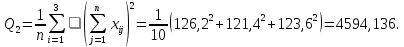
3. Рассчитаем Q3 – квадрат общего итога, деленный на число всех наблюдений:
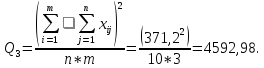
4. Вычислим дисперсии:
-дисперсия, обусловленная фактором А:
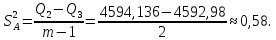
-дисперсия, обусловленная случайными причинами:
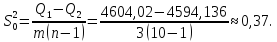
5. Составим соотношение по формуле:
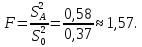
Данное вычисленное значение F сравниваем с критическим Фишера при a=0,05 для числа степеней свободы:
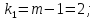
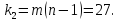
Критическое значение: F1-a,k1,k2=F0,95;2;27=3,35.
Получили, что F<Fкр, значит, влияние вида подготовки на уровень общефизической подготовки не влияет (не является статистической значимой при а=0,05).
Задание 5. Реферат «Основные положения факторного, кластерного и дискриминантного анализа»
Возникновение и развитие факторного анализа тесно связано с измерениями в психологии. Длительное время факторный анализ воспринимался как математическая модель в психологической теории интеллекта. Только лишь начиная с 50-х годов 20 столетия, одновременно с разработкой математического обоснования факторного анализа, этот метод стал общенаучным. К настоящему времени факторный анализ является важной составляющей любой серьезной статистической компьютерной программы и входит в основной инструментарий всех наук, имеющих дело с многопараметрическим описанием изучаемых объектов, таких, как социология, экономика, биология, медицина и другие.
Основная идея факторного анализа была сформулирована еще Ф. Гальтоном, основоположником измерений индивидуальных различий. Она сводится к тому, что если несколько признаков, измеренных на группе индивидов, изменяются согласованно, то можно предположить существование одной общей причины этой совместной изменчивости — фактора как скрытой (латентной), непосредственно не доступной измерению переменной. Далее К. Пирсон в 1901 году выдвигает идею «метода главных осей», а Ч. Спирмен, отстаивая свою однофакторную концепцию интеллекта, разрабатывает математический аппарат для оценки этого фактора, исходя из множества измерений способностей. В своей работе, опубликованной в 1904 году, Ч. Спирмен показал, что если ряд признаков попарно взаимосвязываются друг с другом, то может быть составлена система линейных уравнений, связывающих все эти признаки, один общий фактор «общей одаренности» и по одному специфическому фактору «специальных способностей» для каждой переменной. Стоун впервые предлагает «многофакторный анализ» для описания многочисленных измеренных способностей меньшим числом общих факторов интеллекта, являющихся линейной комбинацией этих исходных способностей. С 1950-х годов, с появлением компьютеров, факторный анализ начинает очень широко использоваться в психологии при разработке тестов, обоснования структурных теорий интеллекта и личности. При этом исследователь начинает с множества измеренных эмпирических показателей, которые при помощи факторного анализа группируются по факторам (изучаемым свойствам).
Факторы получают интерпретацию по входящим в них переменным, затем отбираются наиболее «весомые» показатели этих факторов, отсеиваются малозначимые переменные, вычисляются значения факторов для испытуемых и сопоставляются с внешними эмпирическими показателями изучаемых свойств.
В дальнейшем, по мере развития математического обеспечения факторного анализа, накопления опыта его использования, прежде всего в психологии, задача факторного анализа обобщается. Как общенаучный метод, факторный анализ становится средством для замены набора коррелирующих измерений существенно меньшим числом новых переменных (факторов).
При этом основными требованиями являются:
а) минимальная потеря информации, содержащейся в исходных данных;
б) возможность представления (интерпретации) факторов через исходные переменные.
Таким образом, главная цель факторного анализа — уменьшение размерности исходных данных с целью их экономного описания при условии минимальных потерь исходной информации. Результатом факторного анализа является переход от множества исходных переменных к существенно меньшему числу новых переменных — факторов. Фактор при этом интерпретируется как причина совместной изменчивости нескольких исходных переменных.
Если исходить из предположения о том, что корреляции могут быть объяснены влиянием скрытых причин — факторов, то основное назначение факторного анализа — анализ корреляций множества признаков.
Дискриминантный анализ представляет собой альтернативу множественного регрессионного анализа для случая, когда зависимая переменная представляет собой не количественную (номинативную) переменную. При этом дискриминантный анализ решает, по сути, те же задачи, что и множественный регрессионный анализ (МРА): предсказание значений «зависимой» переменной, в данном случае — категорий номинативного признака; определение того, какие «независимые» переменные лучше всего подходят для такого предсказания. Структуры исходных данных для дискриминантного и множественного регрессионного анализа практически идентичны:
|
№ |
X1 |
X2 |
. . . |
XР |
Y |
|
1 |
x11 |
x12 |
. . . |
х1Р |
Y1 |
|
2 |
x21 |
x22 |
. . . |
х2Р |
Y2 |
|
. . . |
. . . |
. . . |
. . . |
. . . |
. . . |
|
N |
XN1 |
XN2 |
. . . |
XNP |
YN |
Строки этой таблицы соответствуют объектам (испытуемым), а столбцы — переменным. Переменные хиXр представлены в количественной шкале. Различие исходных данных для дискриминантного и множественного регрессионного методов заключается лишь в том, что представляет собой «зависимая» переменная Y: для МРА она является количественной, а для дискриминантного анализа — номинативной (классифицирующей) переменной.
В то же время дискриминантный анализ можно определить и как метод классификации, так как «зависимая» переменная — номинативная, то есть она классифицирует испытуемых на группы, соответствующие разным ее градациям. В этом смысле исходными данными для дискриминантного анализа является группа объектов (испытуемых), разделенная на G классов так, что каждый объект отнесен к одному и только одному классу (градации номинативной переменной).
Допускается при этом, что некоторые объекты не отнесены к какому-либо из этих классов (являются «неизвестными»).
Для каждого из объектов имеются данные по Р количественным признакам, одним и тем же для этих объектов. Эти количественные признаки называются дискриминантными переменными. Задачами дискримшантного анализа являются: определение решающих правил, позволяющих по значениям дискриминантных переменных отнести каждый объект (в том числе и «неизвестный») к одному из известных классов; определение «веса» каждой дискриминантной переменной для разделения объектов на классы
Таким образом, дискриминантный анализ позволяет решить две группы проблем:
1. Интерпретировать различия между классами, то есть ответить на вопросы: насколько хорошо можно отличить один класс от другого, используя данный набор переменных; какие из этих переменных наиболее существенны для различения классов. Сходную задачу решает дисперсионный анализ.
2.Классифицировать объекты, то есть отнести каждый объект к одному из классов, исходя только из значений дискриминантных переменных. Задача классификации связана с получением по данным об «известных» объектах дискриминантных функций «решающих правил», позволяющих по значениям дискриминантных переменных отнести с известной вероятностью каждый объект к одному из классов.
В решении задачи классификации дискриминантный анализ является не заменимым другими методами. Часто дискриминантный анализ называют еще «классификацией с обучением» или «распознаванием образов». В первом случае предполагают, что мы «учимся» классифицировать «неизвестные» объекты по дискриминантным переменным, используя данные об «известных» объектах. Во втором случае под «образом» объекта подразумевается совокупность измеренных для него значений дискриминантных переменных. И дискриминантный анализ позволяет в этом смысле распознать образ «нового» объекта путем отнесения его к известному классу объектов.
Кластерный анализ решает задачу построения классификации, то есть разделения исходного множества объектов на группы (классы, кластеры).
При этом предполагается, что у исследователя нет исходных допущений ни о составе классов, ни об их отличии друг от друга. Приступая к кластерному анализу, исследователь располагает лишь информацией о характеристиках (признаках) для объектов, позволяющей судить о сходстве (различии) объектов, либо только данными об их попарном сходстве (различии).
В литературе часто встречаются синонимы кластерного анализа: автоматическая классификация, таксономический анализ, анализ образов (без обучения).
Несмотря на то, что кластерный анализ известен относительно давно (впервые изложен Тгуоп в 1939 году), распространение эта группа методов получила существенно позже, чем другие многомерные методы, такие, как факторный анализ. Лишь после публикации книги «Начала численной таксономии» биологами Р. Сокэл и П. Снит в 1963 году начинают появляться первые исследования с использованием этого метода. Тем не менее, до сих пор в психологии известны лишь единичные случаи удачного применения кластерного анализа, несмотря на его исключительную простоту. Вызывает удивление настойчивость, с которой психологи используют для решения простой задачи классификации (объектов, признаков) такой сложный метод, как факторный анализ. Вместе с тем, как будет показано в этой главе, кластерный анализ не только гораздо проще и нагляднее решает эту задачу, но и имеет несомненное преимущество: результат его применения не связан с потерей даже части исходной информации о различиях объектов или корреляции признаков.
Варианты кластерного анализа — это множество простых вычислительных процедур, используемых для классификации объектов. Классификация объектов — это группирование их в классы так, чтобы объекты в каждом классе были более похожи друг на друга, чем на объекты из других классов. Более точно, кластерный анализ — это процедура упорядочивания объектов в сравнительно однородные классы на основе попарного сравнения этих объектов по предварительно определенным и измеренным критериям.
Существует множество вариантов кластерного анализа, но наиболее широко используются методы, объединенные общим названием иерархический кластерный анализ (Hierarchical Cluster Analysis)
Кластерный анализ — это комбинаторная процедура, имеющая простой и наглядный результат. Широта возможного применения кластерного анализа очевидна настолько же, насколько очевиден и его смысл. Классифицирование или разделение исходного множества объектов на различающиеся группы — всегда первый шаг в любой умственной деятельности, предваряющий поиск причин обнаруженных различий.
Можно указать ряд задач, при решении которых кластерный анализ является более эффективным, чем другие многомерные методы:
- разбиение совокупности испытуемых на группы по измеренным признакам с целью дальнейшей проверки причин межгрупповых различий по внешним критериям, например, проверка гипотез о том, проявляются ли типологические различия между испытуемыми по измеренным признакам;
- применение кластерного анализа как значительно более простого и наглядного аналога факторного анализа, когда ставится только задача группировки признаков на основе их корреляции;
- классификация объектов на основе непосредственных оценок различий между ними (например, исследование социальной структуры коллектива по данным социометрии — по выявленным межличностным предпочтениям).
Несмотря на различие целей проведения кластерного анализа, можно выделить общую его последовательность как ряд относительно самостоятельных шагов, играющих существенную роль в прикладном исследовании:
1. Отбор объектов для кластеризации. Объектами могут быть, в
зависимости от цели исследования:
а) испытуемые;
б) объекты, которые оцениваются испытуемыми;
в) признаки, измеренные на выборке испытуемых.
- Определение множества переменных, по которым будут различаться объекты кластеризации. Для испытуемых — это набор измеренных признаков, для оцениваемых объектов — субъекты оценки, для признаков — испытуемые. Если в качестве исходных данных предполагается использовать результаты попарного сравнения объектов, необходимо четко определить критерии этого сравнения испытуемыми (экспертами).
- Определение меры различия между объектами кластеризации. Это первая проблема, которая является специфичной для методов анализа различий: многомерного шкалирования и кластерного анализа.
- 4.Выбор и применение метода классификации для создания групп сходных объектов. Это вторая и центральная проблема кластерного анализа. Ее весомость связана с тем, что разные методы кластеризации порождают разные группировки для одних и тех же данных. Хотя анализ и заключается в обнаружении структуры, наделе в процессе кластеризации структура привносится в данные, и эта привнесенная структура может не совпадать с реальной.
5.Проверка достоверности разбиения на классы.
Последний этап не всегда необходим, например, при выявлении социальной структуры группы. Тем не менее следует помнить, что кластерный анализ всегда разобьет совокупность объектов на классы, независимо от того, существуют ли они на самом деле. Поэтому бесполезно доказывать существенность разбиения на классы, например, на основании достоверности различий между классами по признакам, включенным в анализ. Обычно проверяют устойчивость группировки — на повторной идентичной выборке объектов. Значимость разбиения проверяют по внешним критериям — признакам, не вошедшим в анализ.